ALBERT
앞서 배웠던 사전학습 언어 모델들은 굉장히 많은 메모리, 시간과 같은 리소스를 필요로했습니다.
이를 경량화하기 위해서 개발된 것이 ALBERT 입니다.
어떠한 방법들을 사용했을까요?
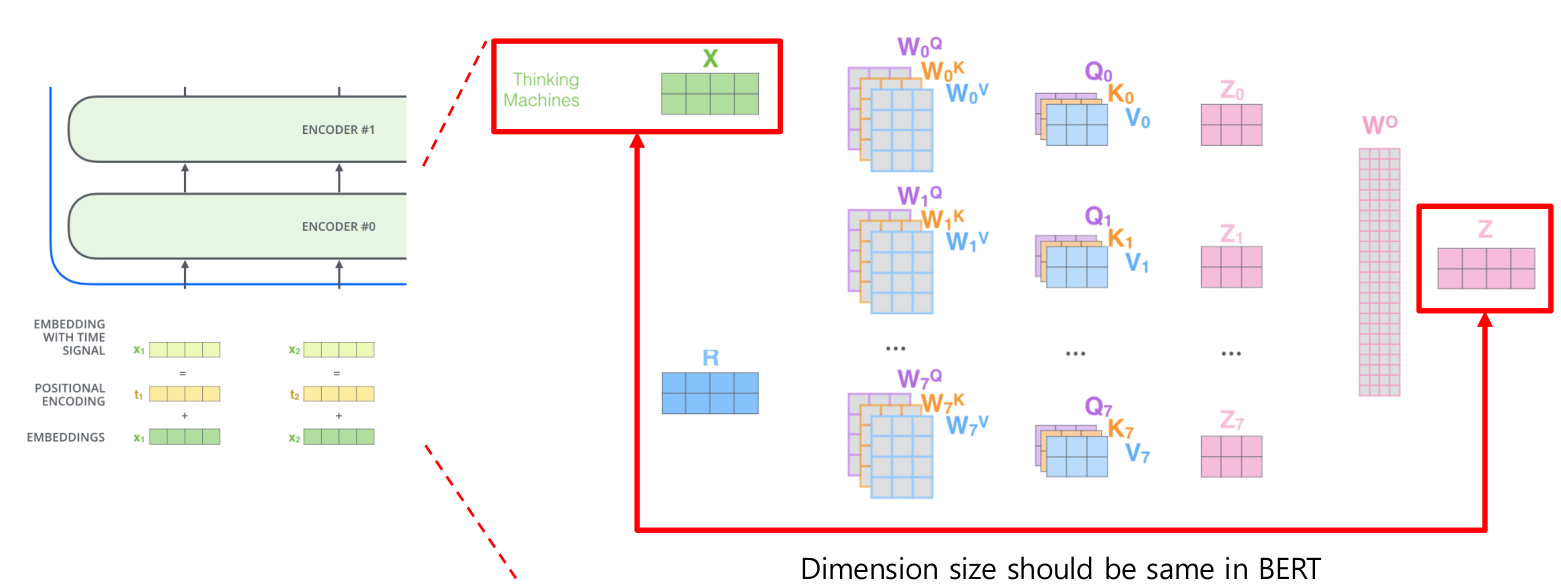
BERT의 경우에는 입력에 사용되는 단어 임베딩 벡터의 차원 수 부터, 최종 hidden state 벡터의 차원수 까지 모두 동일합니다.
아래 그림에서 처럼 X와 Z가 동일한 차원을 가지고 있지요!
그렇다고 차원수를 너무 줄이면, 정보를 많이 표현할 수 없고, 차원수를 키우면 메모리 감당이 어려워 질것입니다.
ALBERT는 이러한 문제를 보완하기 위해 Factorized Embedding Parameterization를 활용했습니다.
임베딩 차원을 줄여 모델의 크기를 줄일 수 있는 획기적인 방법을 제시한 것이지요.
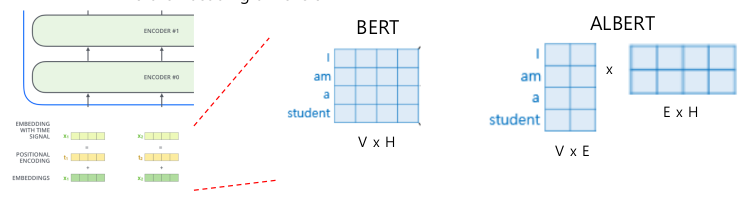
아래 그림을 한번 살펴 보겠습니다.
- V: 단어 크기
- H: hidden-state 차원 수
- E: 단어 임베딩 벡터 차원수
BERT의 경우 V X H 크기의 메트릭스를 가질 수 밖에 없었습니다.
ALBERT의 경우, 단어 임베딩 벡터의 크기를 줄이고, 이를 동일한 크기로 변환할 수 있는 과정을 추가했군요!
실제로 모델의 크기는 얼마나 감소했을까요? 다음 예시를 한번 살펴보세요!
- V= 500, H= 100, E= 10
- BERT: 500 * 100= 50,000
- ALBERT: 500 * 10 + 10 * 100 = 6,000
또 다른 전략으로는 Cross-layer Parameter Sharing이 있습니다.
바로 파라미터를 공유하는 전략입니다.
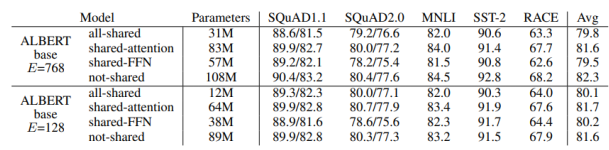
공유되는 파라미터가 많을 수록 모델의 크기를 줄일 수 있지요! 다음 표를 한번 확인해보세요!
- Shared-FFN: feed-forward network 파리미터만 공유
- Shared-attention: attention 파리미터만 공유
- All-shared: 둘다 공유
- Not-shared: BERT
ALBERT 연구진들은 모델의 크기 감소 뿐만아니라 사전 학습 태스크에도 변화를 주었습니다.
바로 NSP 태스크를 없애고, Sentence Oreder Prediction(SOP)이라는 태스크를 구성한 것이지요.
연구진들이 NSP 태스크를 제거한 이유는 너무 쉬운 태스크라고 판단했기 때문입니다.
NSP는 원래의 두문장에서 한문장을 다른 문장으로 대체했기 때문에 전혀 다른 내용이나와 쉽게 판별할 수 있었습니다.
SOP는 연속적인 문장을 순서를 바꾸는 방식으로 순서가 맞는지, 틀린지 판단하는 태스크입니다.
따라서 NSP에 비해 문장의 흐름을 파악해야지만 맞출 수 있는 태스크가 되는 것이지요.
SOP를 사전학습 태스크로 적용한 경우, 대부분의 자연어 처리 태스크에서 성능이 높아진것을 확인할 수 있었습니다.

생각해보기
1) NSP, SOP 말고 또 어떤 태스크를 활용하면 언어를 보다 잘 이해시킬 수 있을까요?
참고자료



comment