학습 목표
- 데이터셋을 요약하고, 집계하는 방법을 알아보겠습니다.
핵심 키워드
- df.isnull().sum() / df.isna().sum()
- df.isnull().sum().plot.barh()
- df.describe()
- df.value_counts()
학습하기

학습 목표
- 데이터셋을 요약하고, 집계하는 방법을 알아보겠습니다.
핵심 키워드
- df.isnull().sum() / df.isna().sum()
- df.isnull().sum().plot.barh()
- df.describe()
- df.value_counts()
학습하기
학습 내용
결측치 보기
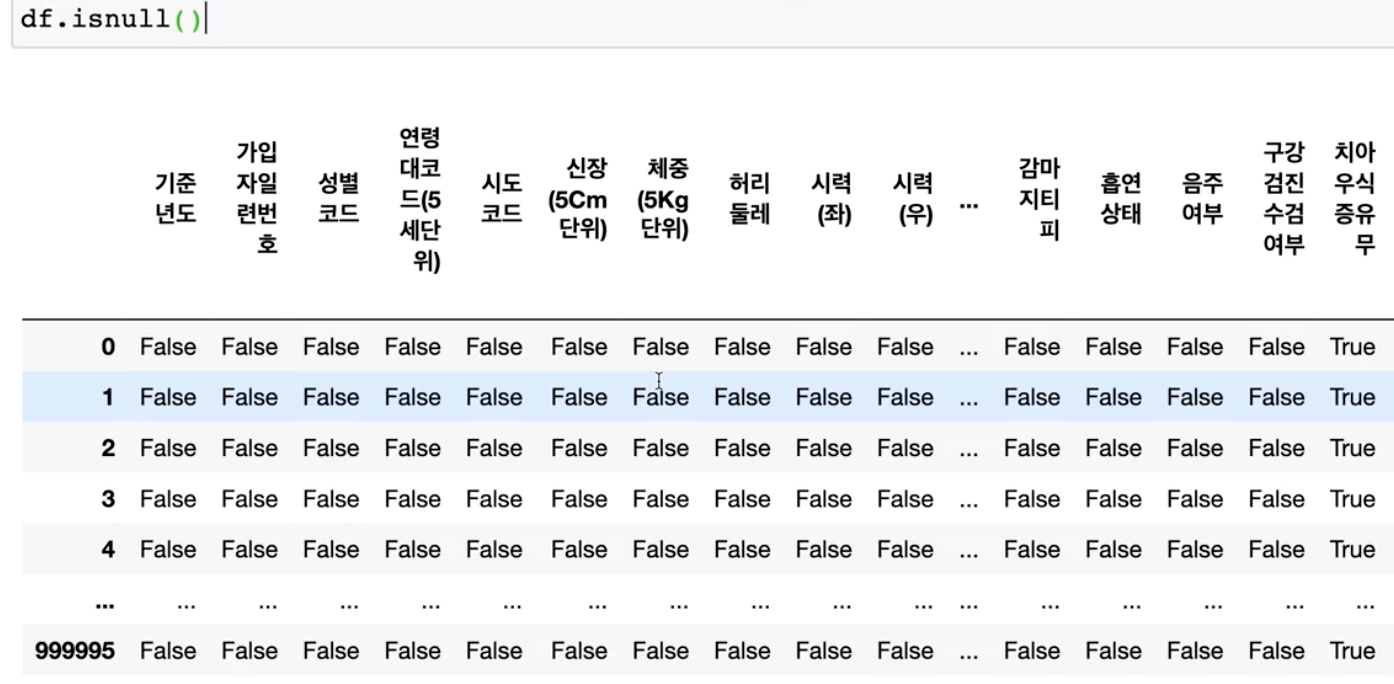
df.isnull()
isnull()으로 결측치를 bool 값으로 표시하고, sum()으로 결측치의 수를 세어줍니다.
'치아우식증유무', '결손치유무', '치아마모증유무', '제3대구치(사랑니 이상)'은 결측치가 있다고 볼 수 있습니다.
결과 :
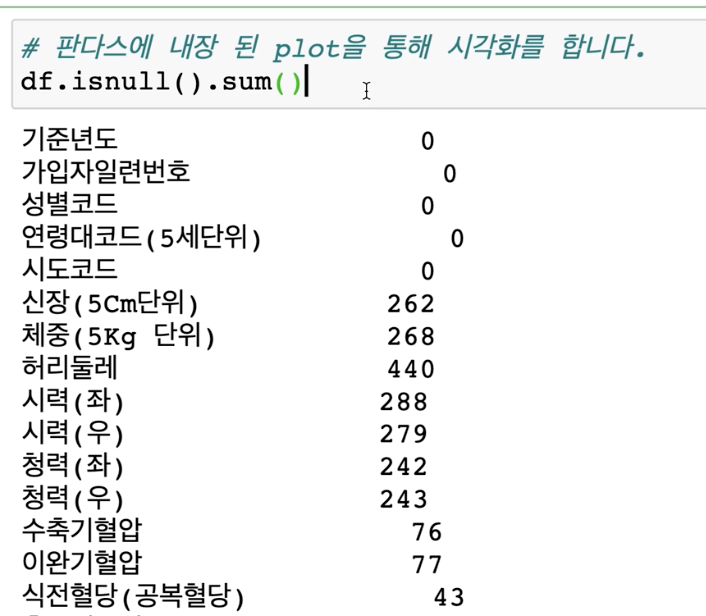
df.isna().sum()
isna()으로도 결측치 수를 집계할 수 있습니다.
결과 :
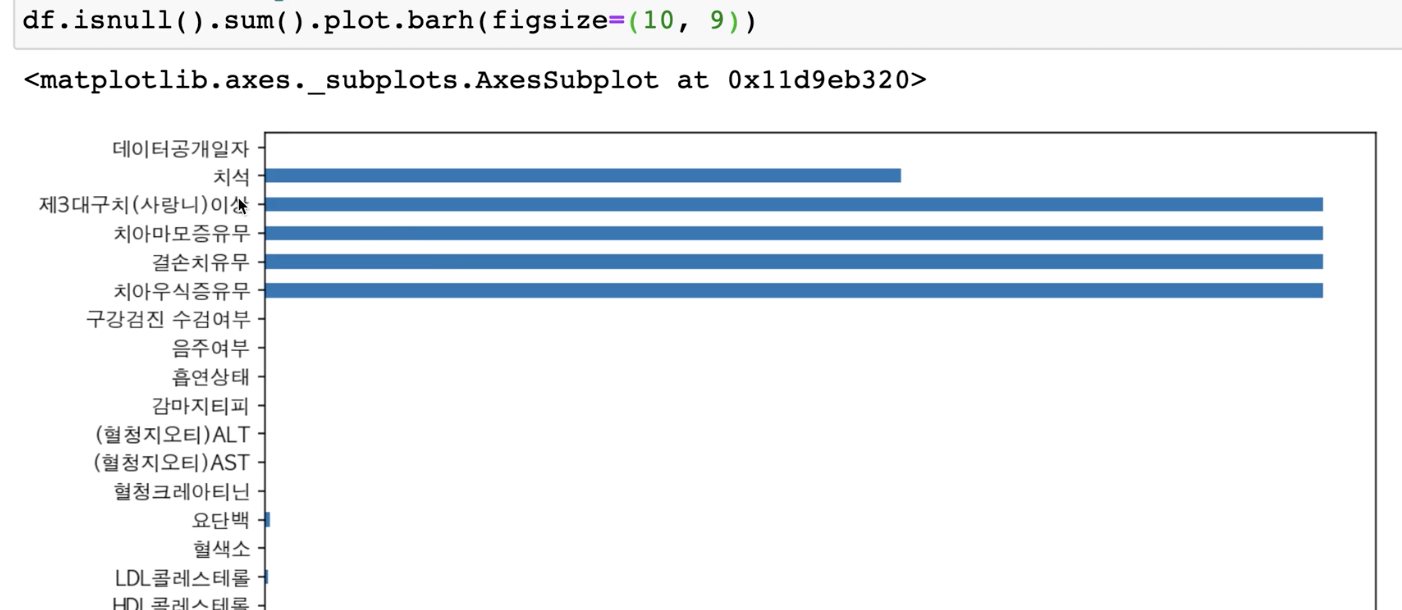
df.isnull().sum().plot.barh(figsize=(10, 9))
pandas에 plot이 내장되어 있어서 가벼운 시각화를 할 수 있습니다.
barh로 글씨를 y축에 두고, figsize 옵션으로 사이즈를 조절할 수 있습니다.
치아 관련 결측치가 커서 다른 결측치들이 상대적으로 작게 보입니다.
결과 :
일부 데이터 요약하기
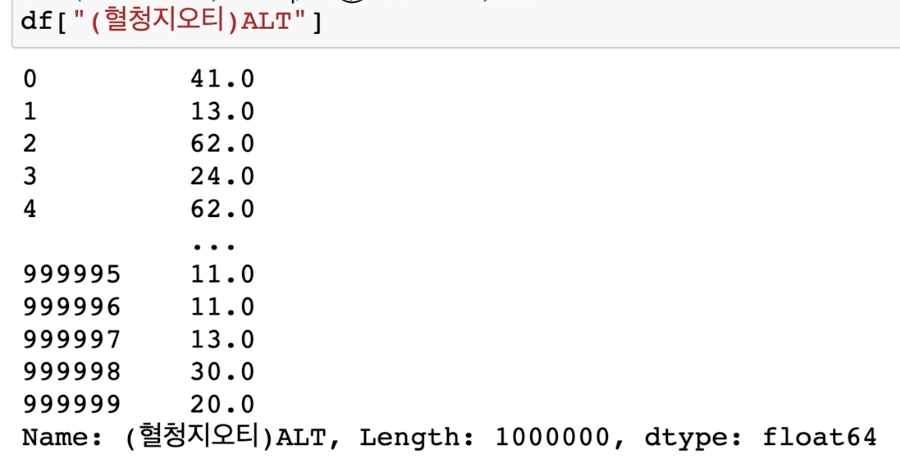
df["(헐청지오티)ALT"]
결과 :
df[["(혈청지오티)ALT","(혈청지오티)AST"]]
2개 이상을 가져올 때는 리스트로 감싸줘야 합니다.
1개의 열을 가져올 때는 series 형태의 데이터 구조로 결과가 나타나고, 2개 이상의 열을 가져올 때는 dataframe 형태의 데이터 구조로 가져옵니다.
결과 :
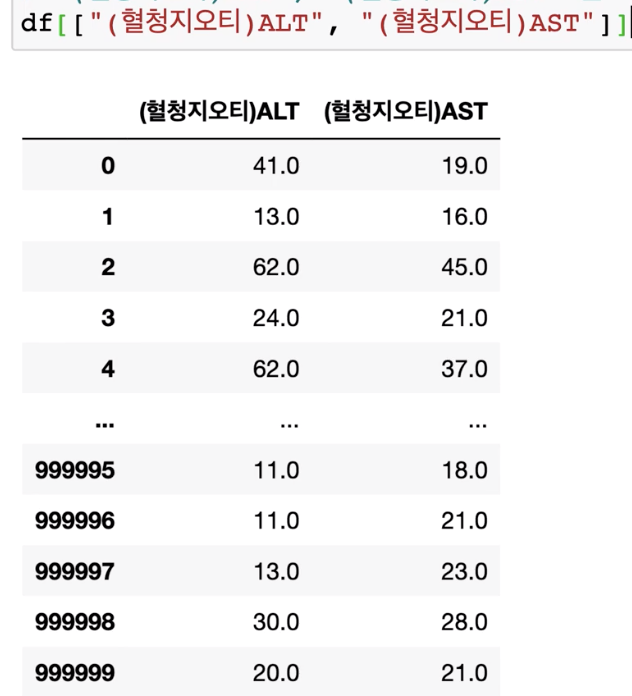
df["(헐청지오티)ALT"].head()5개의 행을 series 형태로 불러옵니다.
결과 :
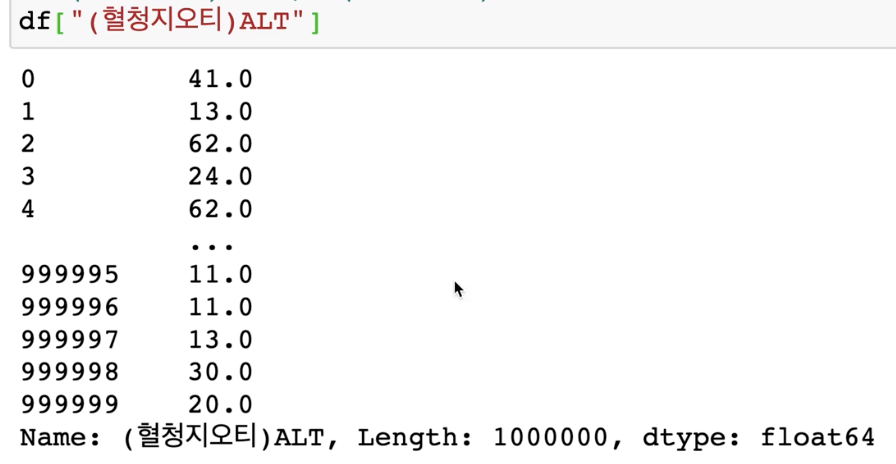
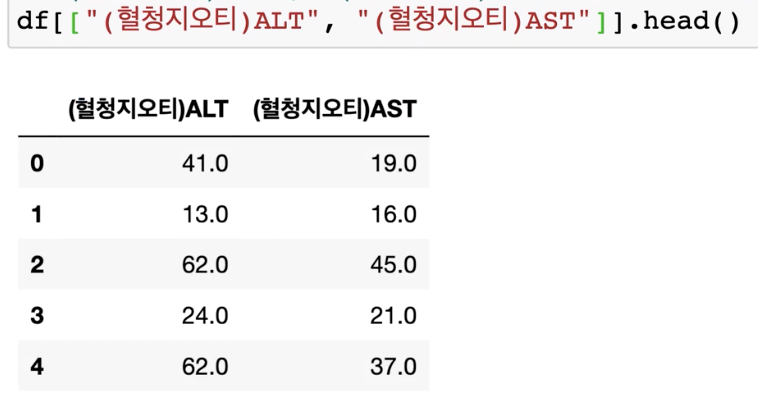
df[["(혈청지오티)ALT","(혈청지오티)AST"]].head()
5개의 행을 dataframe 형태로 불러옵니다.
결과 :
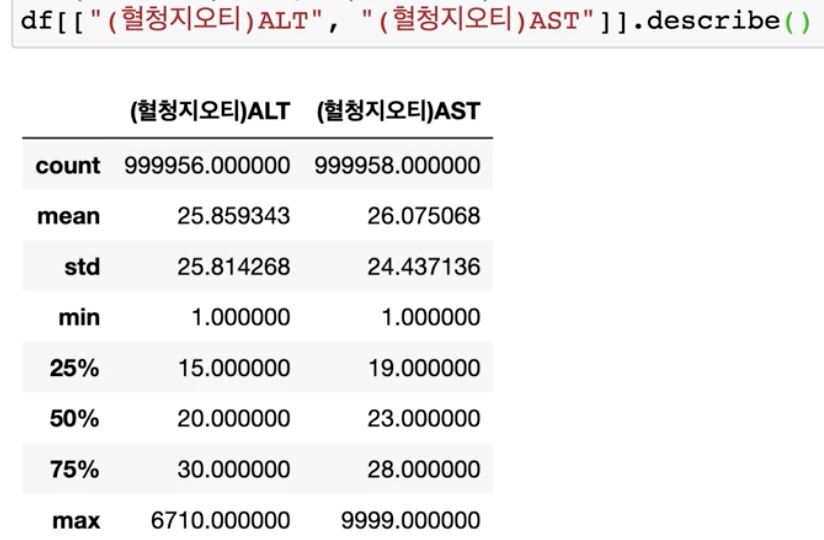
df[["(혈청지오티)ALT","(혈청지오티)AST"]].describe()
수치 데이터에 대한 요약을 볼 수 있습니다.
결측치를 제외한 count 값, mean 값(평균), std 값(표준편차), min 값(최소값), max 값(최대값), 50%(중앙값, 2사분위수), 25%(1사분위수), 75%(3사분위수)를 집계하여 보여줍니다.
중앙값에 비해 평균값이 높다는 걸 알 수 있습니다. 현재 평균값은 max 값에 의해 영향을 많이 받고 있습니다. 이상치가 있습니다.
결과 :
값 집계하기
value_counts()로 category나 text 형태 데이터의 빈도수를 체크할 수 있습니다.
df["성별코드"].value_counts()성별 코드의 값 2개의 갯수를 볼 수 있습니다.
결과 :

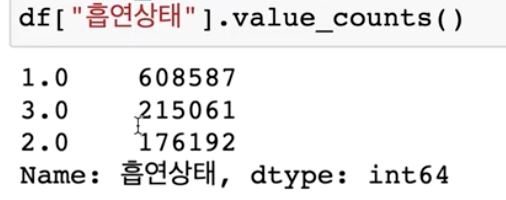
df["흡연상태"].value_counts()
1은 흡연하지 않는 사람, 2는 흡연하는 사람, 3은 흡연했지만 금연한 사람입니다.
공공데이터포털의 링크에 가면 코드값이 의미하는 바를 알 수 있습니다.
결과 :
comment
흡연상태에 대한 요약정리 부분, 수정이 필요해 보입니다:
해당 수검자의 흡연 상태 여부
1(피우지 않는다), 2(이전에 피웠으나 끊었다), 3(현재도 피우고 있다)
공공데이터 개방서비스에서 해당값이 의미하는 코드값은 어디서 볼 수 있나요?
df["흡연상태"].value_counts 구문에서 커서가 태 와 쌍따옴표(") 사이에서 마침표(.) 위치로 이동할때 키보드 key가 무엇일까요??
감사합니다.
오타요
df.isnull().sum().plot.barh(figsize=(10, 9))