학습내용 λ 값을 크게 만들어서 가중치행렬 w 를 0에 가깝게 설정할 수 있습니다. J(w[l],b[l])=m 1σi=1mL(y(i)^,h(i))+2m λσl=1L∣∣w[l]∣∣F2 그 결과로 간단하고 작은 신경망이 되기에 과대적합이 덜 일어납니다. tanh 활성화 함수를 사용했을 경우 λ 값 커지면 비용함수에 의해 w 는 작아지게 되고, 이때 z[l]=w[l]a[l−1]+b[l] 이므로 z 도 작아지게 됩니다.

comment
앞절과 같이 학습내용에 오타입니다.
시그마가 전부 소문자 σ에서 대문자 Σ로 바꾸어야 합니다. 2개 다 바꾸어야 합니다.
비용함수의 loss함수 안에 h^(i)로 되어있는데 y^(i)로 바꾸어야 합니다.
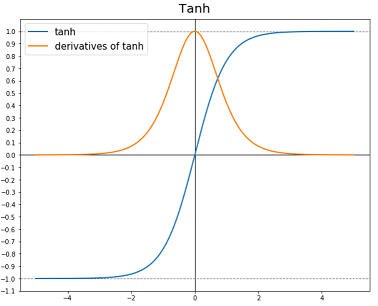
질문하나있습니다.
4:20에 z값이 작아지면 g(z)도 작아져서 거의 선형함수가 된다고 하는데 혹시 z가 음수값을 가지고 계속 작아진다면 기울기값은 올라가지 않나요??