학습목표
- 리스트를 활용하는 다양한 방법을 이해할 수 있다.
- 시퀀스를 표현하는 리스트, 문자열, 튜플의 차이점을 이해한다.
학습하기

학습목표
학습하기
많은 데이터 (이 전 강의에서 이어집니다.)
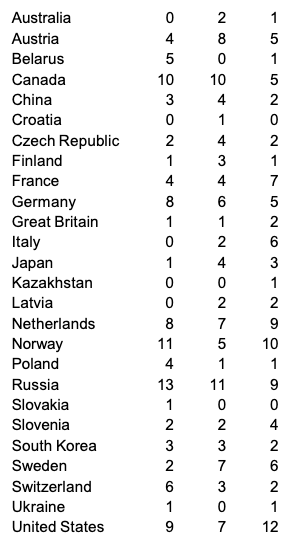
이 데이터를 Python에서 어떻게 저장할 수 있을까요?
하나하나 변수로 만들려면 총 4 × 26개의 변수가 필요하네요..
리스트(List)를 사용하면 여러 값들을 모아서 보관할 수 있습니다.
정렬
리스트는 sort 함수를 이용해 원소들을 정렬할 수 있습니다.

totals 리스트를 정렬해봅시다.

리스트 자르기
리스트의 특정 부분을 잘라내서 새로운 리스트로 만들 수 있습니다 (slicing)
sublist = mylist[i:j]
sublist는 mylist의 인덱스 i,i+1,…,j-1에 해당하는 원소를 포함한 리스트입니다.
i 를 생략하면, sublist는 mylist의 첫 번째 원소부터 가지게 됩니다.
j 를 생략하면, sublist는 mylist의 마지막 원소까지 가지게 됩니다.
다음처럼 쓰면 리스트를 복사할 수 있습니다.
list2 = list1[:]
리스트 뒤집기
다음처럼 리스트를 뒤집어, 메달이 많은 나라가 앞쪽에 오게 할 수 있습니다.

메달이 가장 많은 10개의 나라만 따로 볼 수도 있습니다.

리스트의 원소는 다음처럼 풀어낼 수 있습니다.

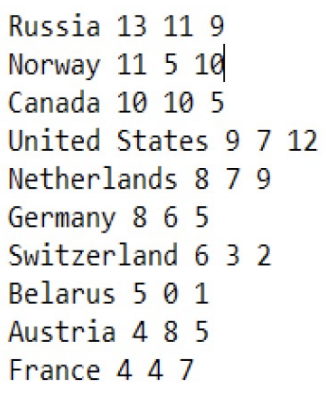
메달 순위
메달 수 상위 10개의 나라를 메달수에 관해 정렬해봅시다.
table = []
for i in range(len(countries)):
table.append( (gold[i], silver[i], bronze[i], countries[i]) )
table.sort()
top_ten = table[-10:]
top_ten.reverse()
for g, s, b, country in top_ten:
print(country, g, s, b)
한 종류의 메달만 획득한 나라
한 종류의 메달만 획득한 나라들을 모두 찾아봅시다.
(메달을 하나도 획득하지 못한 나라는 없다고 가정합니다)
def no_medals(countries, al, bl):
result = []
for i in range(len(countries)):
if al[i] == 0 and bl[i] == 0:
result.append(countries[i])
return result
only_gold = no_medals(countries, silver, bronze)
only_silver = no_medals(countries, gold, bronze)
only_bronze = no_medals(countries, gold, silver)
only_one = only_gold + only_silver + only_bronze
리스트의 멤버 함수
리스트 객체 L은 다음과 같은 멤버 함수들을 가지고 있습니다.
* L.append(v) v 객체를 리스트 끝에 추가
* L.insert(i, v) 객체를 리스트의 i번째 위치에 추가
* L.pop() 리스트의 마지막 원소를 삭제하고, 그 값을 반환
* L.pop(i) i번째 원소를 삭제하고, 그 값을 반환
* L.remove(v) v와 일치하는 첫 번째 원소를 삭제
* L.index(v) v와 일치하는 첫 번째 원소의 위치를 반환
* L.count(v) v와 일치하는 원소들의 개수를 반환
* L.extend(K) K의 모든 원소를 리스트 L 끝에 추가
* L.reverse() 리스트의 모든 원소를 역순으로 재배열
* L.sort() 리스트 정렬
다음 두 코드는 어떤 차이가 있을까요?
L.append(13)
L + [13]
시퀀스
리스트는 시퀀스(Sequence)의 한 종류입니다.
문자열과 튜플 또한 시퀀스의 한 종류입니다.

리스트, 튜플, 문자열
리스트과 튜플은 비슷하지만 큰 차이점이 있습니다.
리스트는 가변 객체지만, 튜플(과 문자열)은 불변 객체입니다.

시퀀스는 list, tuple 함수를 이용해 리스트이나 튜플로 만들 수 있습니다.

메달 리스트
Python에서는 올림픽 메달 집계 정보를 리스트 4개로 만드는 것보다, 튜플들의 리스트로
만드는 방법을 더 많이 사용합니다.

나라별 총 메달 수는 다음처럼 출력할 수 있습니다.
def print_totals1():
for country, g, s, b in medals:
print(country + ":", g + s + b)
def print_totals2():
for item in medals:
print(item[0] + ":", sum(item[1:]))
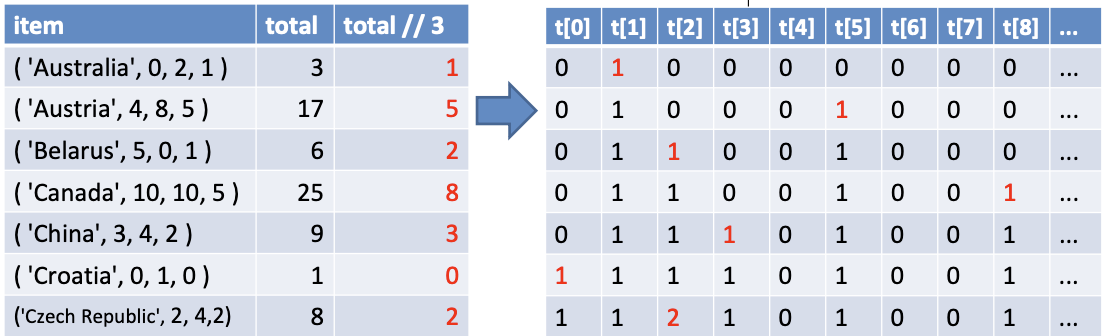
히스토그램
메달 집계 결과로 히스토그램을 만들어 봅시다.
def histogram():
t = [0] * 13
for item in medals:
total = sum(item[1:])
t[total // 3] += 1
for i in range(13):
print (str(3*i) + "~" + str(3*i+2)+":\t"+("*"* t[i]))

참고자료


comment
L.append(13)
L + [13]
이 둘은 어떤 차이가 있는지요?
totals.sort() 는 ★순서대로 정렬을 해주지만
totals.reverse() 는 ★정렬없이 역순으로 배열만 해주는 거였네요~
튜플,리스트 사용 방법이 참 다양하네요.
첨부파일 코드예제에 top_ten() 함수는 잘 안되도 지나쳐야겠습니다. 코드가 조금 생략되었습니다.(실습 목표인 히스토그램은 잘 실행됩니다)
top_ten() 안에 쓰인 compare()함수는 그 안에 cmp 함수가 사용됬는데 cmp는 파이썬2 버전에 쓰던 내장함수이고, 파이썬 3에서는
cmp_to_key 로 바뀌었고 이를 쓰려면 form functools import cmp_to_key로 모듈을 불러와야 하게 바뀌습니다. 이런 부분은 학습목표와 많이 벗어나서 다 뺀 것 같습니다. 이를 다 넣으면 이해하기 무척 어렵겠습니다.
참고로 배열 안의 튜플의 두번째 인덱스 비교하여 정렬하는 방법 중 하나의 예시를 밑에 적습니다. A 배열 안의 튜플의 두 번째 인덱스로 비교 후 작은 값 순으로 정렬을 해주는 알고리즘입니다. (좀 외워야 하는듯 하며 알고리즘 같은데 지금 배울 단계가 아닌듯 싶고 그래서 예제 코드에서 빠진듯 합니다.)
from functools import cmp_to_key
A = [("s",3),("ss",1),("sss",2)]
def cmp(a,b):
return int(a[1]>b[1]) - int(a[1]<b[1]) # a[1], b[1]을 비교해서 1, 0, -1 셋 중 하나를 반환해요.
# print((3>1)-(3<1)) # 이 코드는 예인데 3이 1보다 커서 1을 반환하고, 만약 같으면 0 , 만약 작으면 -1을 반환합니다.
# cmp(("s",3),("ss",1)) # 이 코드 역시 테스트 코드인데요. 숫자 기준으로 잘 정렬합니다.
A.sort(key=cmp_to_key(cmp))
print(A) # [('ss', 1), ('sss', 2), ('s', 3)]
*만약 내림차순으로 정렬하다면 함수 정의를 조금 바꿔줍니다.
def cmp(a,b):
... return -(int(a[1]>b[1]) - int(a[1]<b[1])) # 반환값에 마이너스를 붙여넣었습니다.
질문입니다.
코드예제 중에서 medals2.py 에서 top_ten() 을 실행해보면 오류가 발생합니다.
>>> top_ten()
Traceback (most recent call last):
File "<pyshell#79>", line 1, in <module>
top_ten()
File "<pyshell#78>", line 2, in top_ten
medals.sort(compare)
TypeError: sort() takes no positional arguments
1. 오류가 안나려면 어떻게 수정해야 할까요?
2. medals.sort(compare) 어떤 의미인지 궁금합니다. 강의때는 안나온것 같아서요. 아규먼트를 어떻게 넣어야 하는것인지.
3. compare 함수에서 return -cmp(medals1, medals2) 의 의미를 잘 모르겠습니다.
4. 강의 중 reverse() 부분에서 메달합계가 같으면 나라이름도 내림차순으로 나오는데, 메달합계는 오름차순이고, 나라이름은 내림차순으로 나오려면 어떻게 해야할까요?
할수록 재미있지만, 어려워지네요.
감사합니다.
감사합니다