학습 목표
- 피쳐 스케일링을 진행할 수 있습니다.
핵심 키워드
- StandardScaler()
- fit(), transform()
학습하기

학습 목표
- 피쳐 스케일링을 진행할 수 있습니다.
핵심 키워드
- StandardScaler()
- fit(), transform()
학습하기
학습내용
숫자의 범위가 다르면 feature 별로 비중이 다르게 계산될 수 있으므로 스케일링 기법을 사용하기도 합니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(df[["Glucose", "DiabetesPedigreeFunction"]])
scale = scaler.transform(df[["Glucose", "DiabetesPedigreeFunction"]])
scale
fit을 하고, transform하면 숫자가 변형됩니다.
스케일링한 값을 변수에 담아줍니다. 크게 데이터가 달라지지 않았습니다.
결과 :

df[["Glucose", "DiabetesPedigreeFunction"]] = scale
df[["Glucose", "DiabetesPedigreeFunction"]].head()값이 잘 들어갔는지 확인합니다.
결과 :
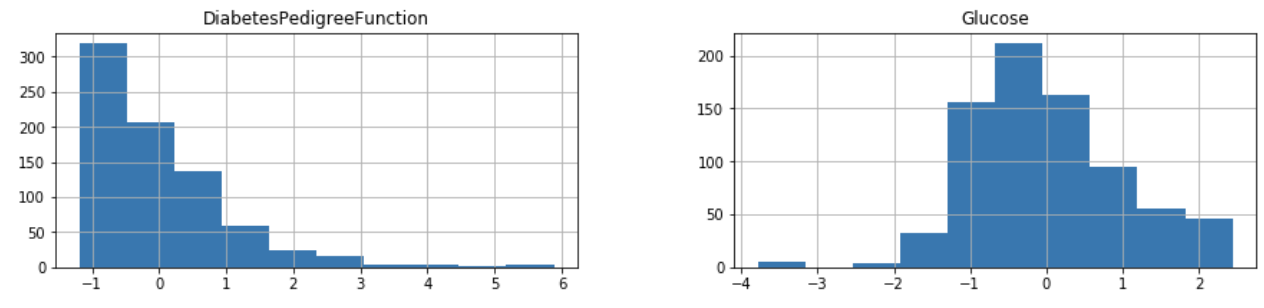
h = df[["Glucose", "DiabetesPedigreeFunction"]].hist(figsize=(15, 3))
범위가 조금 달라졌습니다.
결과 :
이 프로젝트에서는 스케일링이 크게 의미가 없지만 다른 프로젝트에서는 예측의 정확도를 높일 수 있습니다.
전처리는 EDA를 먼저 진행해 인사이트를 얻은 후 진행하는 것이 좋습니다.
https://colab.research.google.com